最近入手学习Python3的网络爬虫开发方向,入手的教材是崔庆才的《python3网络爬虫开发实战》,作为温故所学的内容同时也是分享自己操作时的一些经验与困惑,所以开了这个日记,也算是监督自己去学习。在这一系列的日记中我也会随时加上一些书中没有的内容作为对所学知识的一个补充。
(1)使用urllib库
在python3中,把python2的urllib和urllib2两个库合并了,同时作为了其内置的HTTP请求库,不需要额外安装,这个库包括四个模块
request:最基本的HTTP请求模块,可用来模拟发送请求。传入URL以及额外的参数就可以实现想浏览器那样访问网站
error:异常处理模块,请求错误时,我们可以捕获这些异常,在进行重试以保证程序不意外终止
parse:一个工具模块,提供URL处理方法,比如拆分,解析,合并
robotparser:主要用来识别网站的robots.txt文件,然后判断哪些网站可以爬,用得少。
我们主要了解前三个模块
首先是安装,直接用命令安装 pip install urllib3(这里如果不打3的话在cmd中会报错)(ps:吐槽的是别少打一个l)

接下来我们用request发送请求,可以使用以下一些函数
1. urlopen():可请求抓取网页内容
如下请求python官网的内容
1 import urllib.request2 response = urllib.request.urlopen('https://www.python.org')3 print(response.read().decode('utf-8'))
使用type()函数可以发现他的类型
print(type(response))
是一个HTTPResponse类型的对象,因此可对其进行一些方法使用,如read()可返回网页内容,status可得到返回结果的状态码,如200代表请求成功,404代表网页未找到
值得一提的是如果read 函数后未接decode('utf-8')那么现实的会是 b''因为网页是二进制,需要将其转为utf-8格式才行
>>> print(response.read())b''
利用response下的方法来找到状态码和响应的头信息,最后是获取了其中Server值,nginx表示服务器是用Nginx搭建的
>>> print(response.status)200>>> print(response.getheaders())[('Server', 'nginx'), ('Content-Type', 'text/html; charset=utf-8'), ('X-Frame-Options', 'SAMEORIGIN'), ('x-xss-protection', '1; mode=block'), ('X-Clacks-Overhead', 'GNU Terry Pratchett'), ('Via', '1.1 varnish'), ('Content-Length', '48812'), ('Accept-Ranges', 'bytes'), ('Date', 'Thu, 16 Aug 2018 02:31:55 GMT'), ('Via', '1.1 varnish'), ('Age', '595'), ('Connection', 'close'), ('X-Served-By', 'cache-iad2126-IAD, cache-hnd18734-HND'), ('X-Cache', 'HIT, HIT'), ('X-Cache-Hits', '59, 109'), ('X-Timer', 'S1534386716.758723,VS0,VE0'), ('Vary', 'Cookie'), ('Strict-Transport-Security', 'max-age=63072000; includeSubDomains')]>>> print(response.getheader('Server'))nginx
还可以给urlopen传递一些参数,我们可以看看该函数的API(应用程序调用接口)
urllib.request.urlopen(url , data=None , [timeout,]* , cafile=None , capath=None , cadefault=False , context=None)
下面对这几个参数进行调用:
这里要注意一个事,使用与urllib相关的库时候,文件的命名千万别用一些敏感词,比如http.py,否则在导入包的时候,会一直报错说module 'urllib' has no attribute 'request'
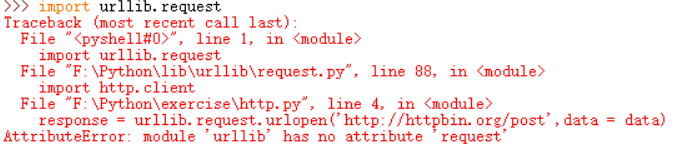
后面将名字改了后就没有出现相关的报错了 ,当然出现这种报错还有一种原因,那就是导入的时候直接导入的是import urllib。但是在python3中,他不会把子模块一块导入,所以我们需要具体的导入比如import.urllib.request ,当然还有最后一种错误,那就是你拼错了单词,这就是一段辛酸泪了,好了,接下来我们开始进行各个参数的调试。
- data参数
该参数是可选的,如果要添加该参数,如果他是字节流编码格式,即为bytes类型的话,则需要使用bytes()方法转化另外如果传递了这个参数,他的请求方式就不再是GET, 而是POST。
import urllib.requestimport urllib.parsedata = bytes(urllib.parse.urlencode({'word':'hello'}),encoding = 'utf8')response = urllib.request.urlopen('http://httpbin.org/post',data = data)print(response.read()) 结果为
b'{ "args": {}, "data": "", "files": {}, "form": { "word": "hello" }, "headers": { "Accept-Encoding": "identity", "Connection": "close", "Content-Length": "10", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "Python-urllib/3.6" }, "json": null, "origin": "182.110.15.26", "url": "http://httpbin.org/post" }
传递的参数出现在了form字段中,表明是模拟了表单的提交方式,以POST传递了数据
- timeout 参数
timeout参数用于设置超时时间,单位为秒,意思为如果超过了设置的这个时间,还没有得到响应,就会抛出异常。如果不指定该参数,就会使用全局默认时间,
它支持HTTP,HTTPS,FTP请求。
import urllib.requestresponse = urllib.request.urlopen('http://httpbin.org/post',timeout=1)print(response.read())
设置超时时间为1秒,结果一秒后,服务器无响应,于是抛出了URLError异常。该模块属于urllib.error模块,错误原因为超时。
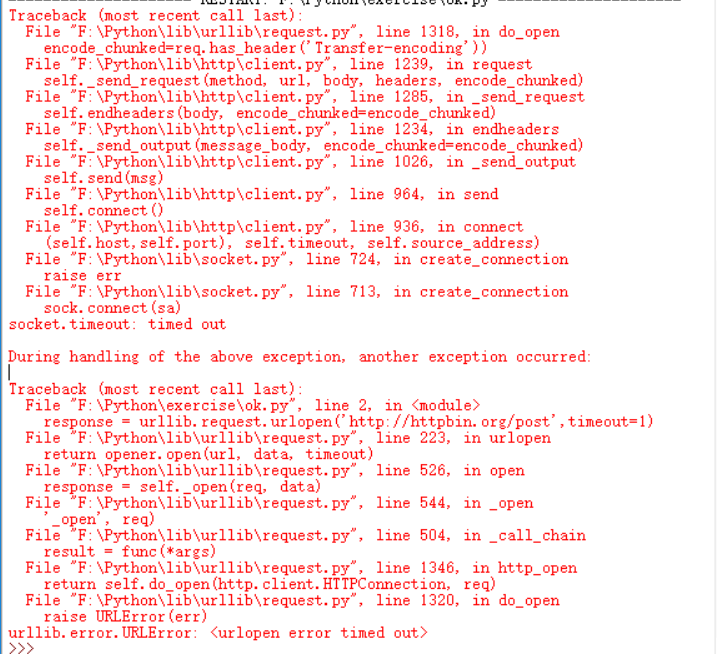
因此我们可以设置超时时间为来控制网络长时间未反应,,也就是跳过他的抓取。可以使用try expcept语句实现。
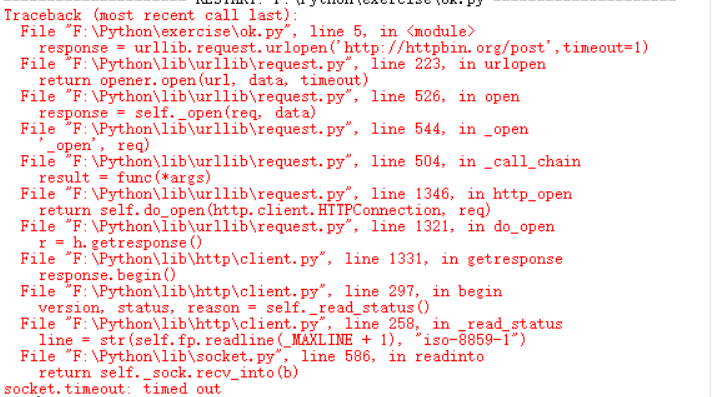
其中,isinstance()函数的API为isinatance(object,classinfo),object为实例对象,classinfo为直接或间接类名,值得一提的是他与type的区别,type不会认为子类是父类的一种类型,但isintance会认为子类是父类的一种类型。
socket.timeout为超时类型。
- 其他参数:
还有其他一些参数如context参数,他必须是ssl.SSLConetext,用来指定SSL设置(SSL:(Secure Socket Layer,安全套接层协议),SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。SSL通过互相认证、使用数字签名确保完整性、使用加密确保机密性,以实现客户端和服务器之间安全通讯。该协议由两层组成:SSL记录协议和SSL握手协议。)
此外还有cafile参数指定CA证书,capath参数指定他的路径,这个在请求HTTPS链接时会有效